ChipMATE
Two AI agents learn to write and verify chip hardware code together — no cloud APIs, no golden testbench.
The Problem
Current AI systems for generating Register-Transfer Level (RTL) hardware code face a three-way deadlock: they need golden testbenches that don't exist before the design is written, rely on cloud APIs that violate chip vendors' air-gap security, and can't be trained on companies' most valuable asset — their proprietary RTL codebases.
Self-trained models fix the deployment issue but remain single-turn generators with no ability to check their own output. Even senior engineers rarely write correct RTL in one attempt — why should a model?
The Idea
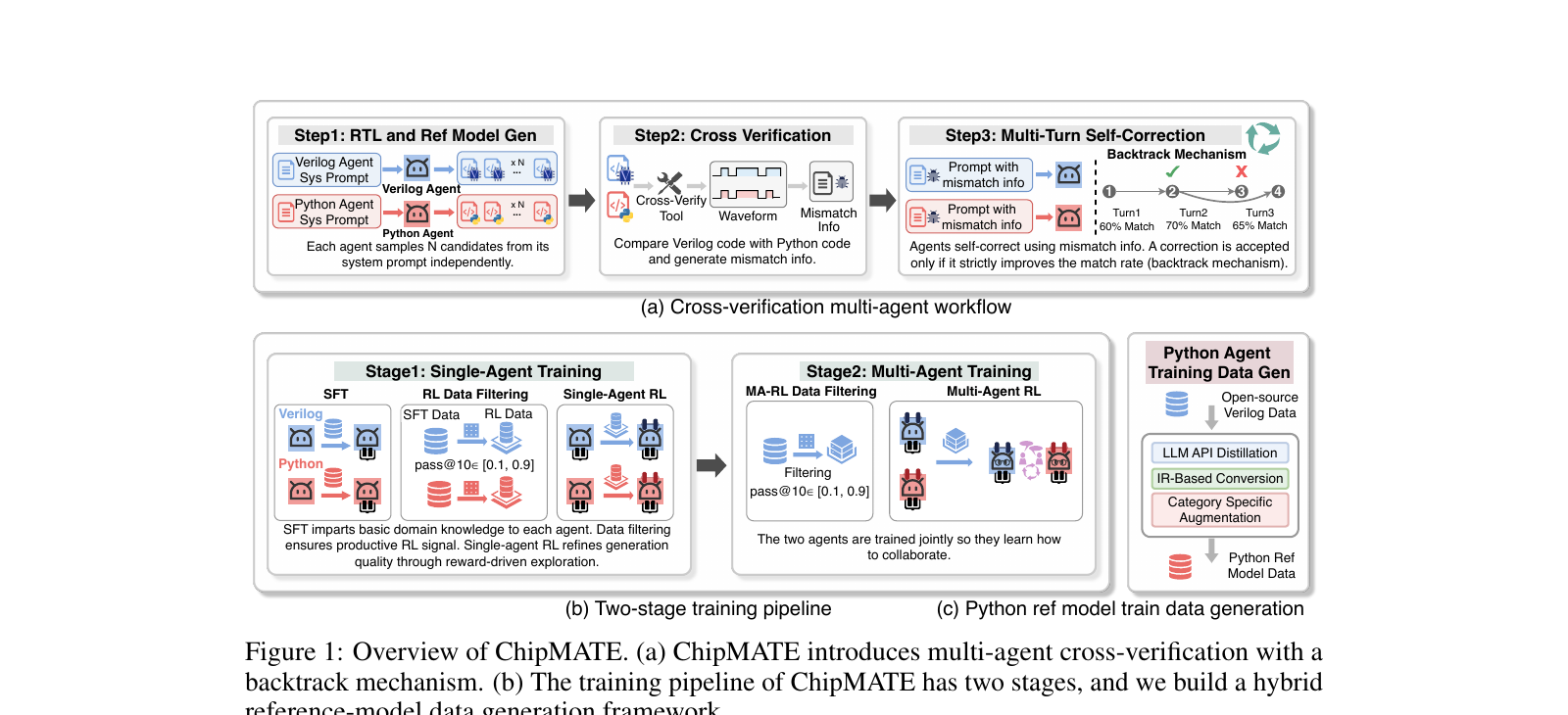
Real chip design doesn't rely on a single perfect engineer — it uses cross-verification between a design team writing RTL and a verification team writing reference models. ChipMATE mirrors this: a Verilog agent and a Python reference-model agent mutually verify each other's outputs, iteratively fixing bugs without any ground-truth reference. A backtrack mechanism prevents error propagation by accepting corrections only when they strictly improve the match rate.
How It Works
Cross-Verification Workflow
A Verilog agent and Python agent each generate N candidates independently, then a cross-language tool compares their cycle-by-cycle outputs on 1000 random stimuli and produces mismatch diagnostics.
Two-Stage Training
Stage 1 trains each agent solo (SFT + RL) to maximize individual code quality. Stage 2 trains them jointly with multi-agent RL and a novel X-GRPO algorithm so they learn to collaborate.
Reference-Model Data Generation
A hybrid framework combines LLM API distillation, IR-based Verilog-to-Python conversion, and category-specific augmentation to produce 64.4K high-quality training samples from scratch.
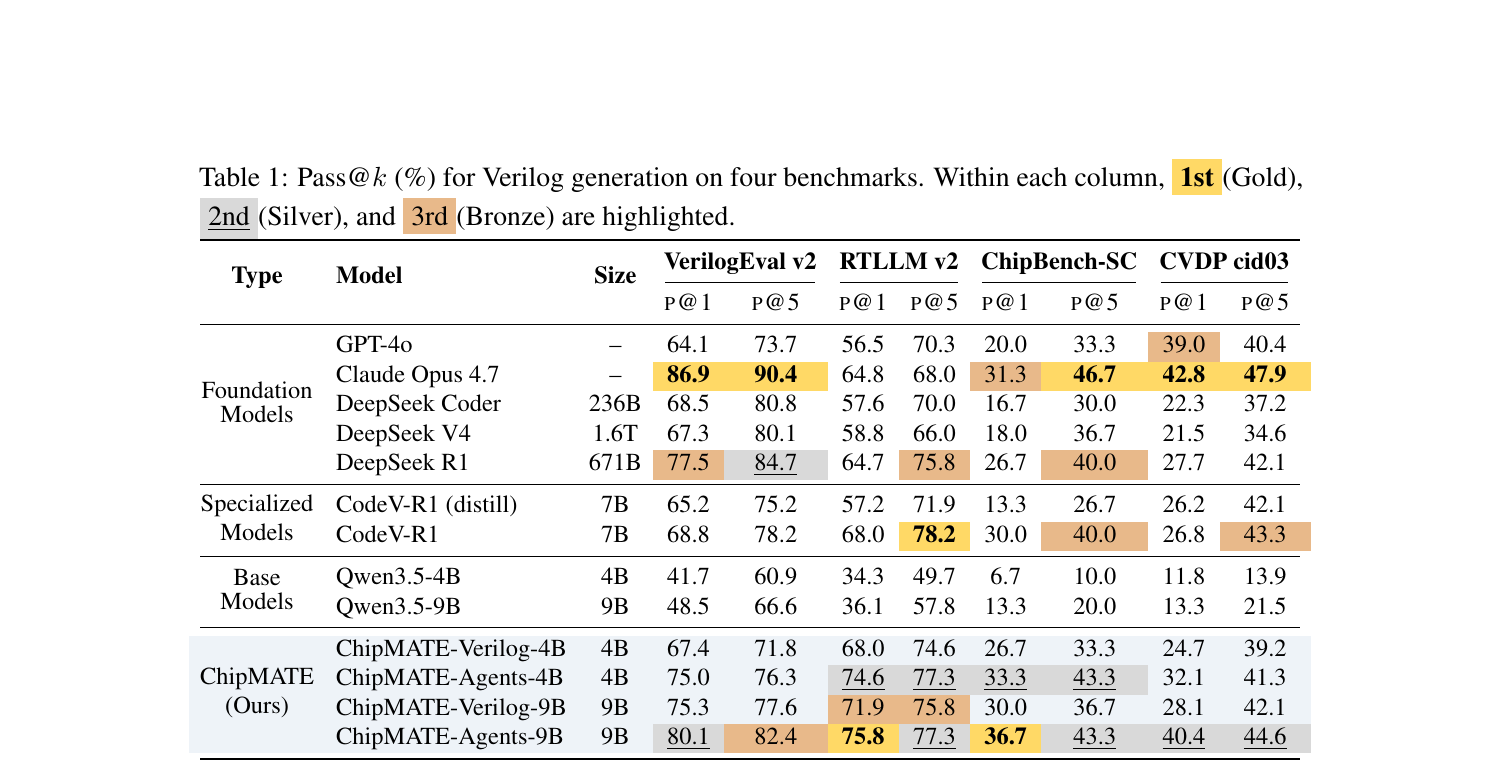
Results
On VerilogEval v2, ChipMATE-Agents-9B hits 80.1% pass@1 — outperforming all existing self-trained models and even DeepSeek V4 (1.6T parameters). The smaller 4B variant still achieves 75.0% pass@1, beating prior SOTA CodeV-R1 (7B) by 6.2%.
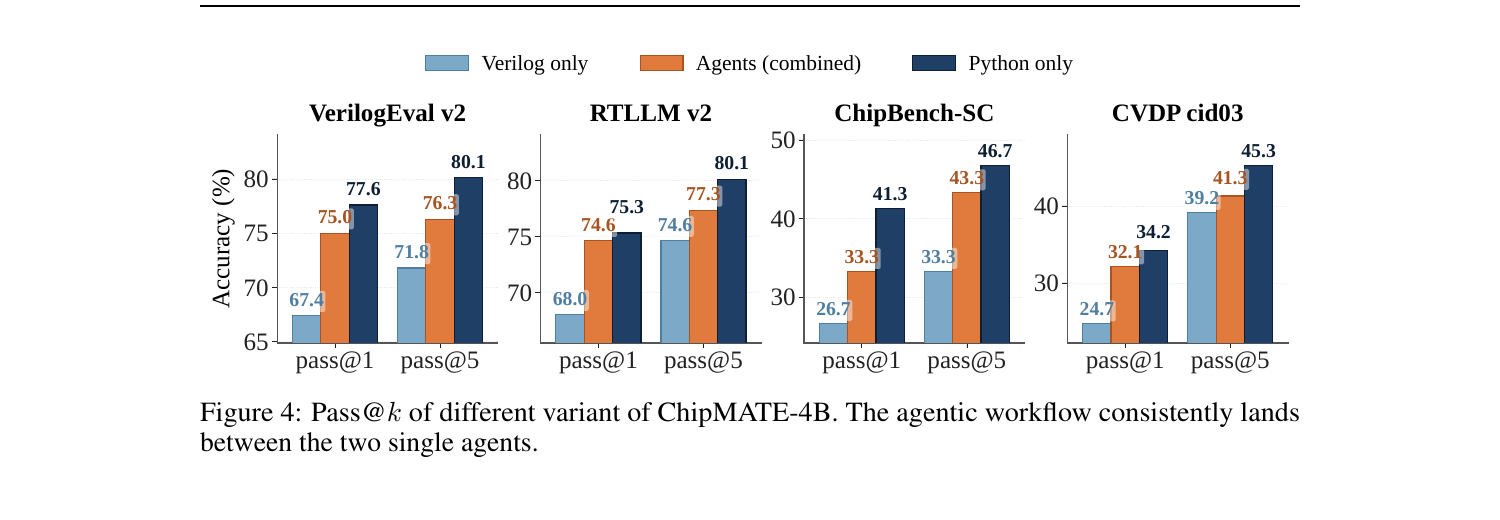
See the paper for full ablations, workflow exploration, and per-benchmark breakdowns.
Limitations
Paper & Code
Model weights, inference workflow, and training dataset will be open-sourced upon publication.